

ByteDance officially integrated its new audio and video generation model, Dreamina Seedance 2.0, into the CapCut editing platform this Thursday, enabling creators to generate, edit, and sync content via text prompts, images, or reference videos.
Phased Global Rollout
The company is initiating a phased rollout, currently limiting access to users in Brazil, Indonesia, Malaysia, Mexico, the Philippines, Thailand, and Vietnam. This strategy follows reports that the global launch was temporarily paused to address alleged copyright infringement concerns raised by Hollywood stakeholders. In China, the model remains available through the Jianying app.
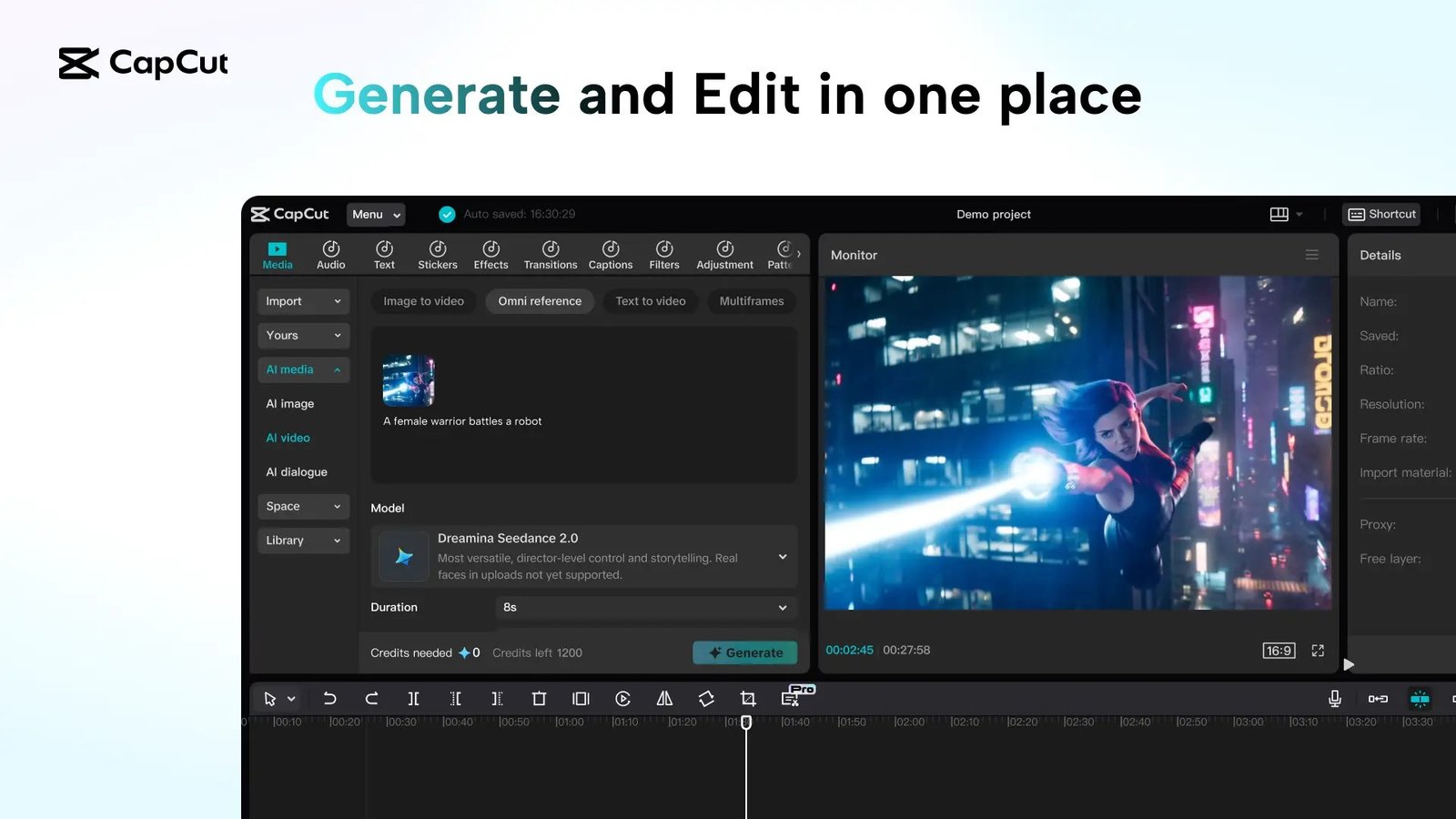
Technical Capabilities and Use Cases
According to the company’s announcement, the model functions without requiring reference images, utilizing descriptive text to generate video. It excels at rendering realistic textures, movement, and lighting, allowing users to edit or enhance existing footage. Beyond simple generation, the model serves as a prototyping tool for testing concepts before full-scale production. It is designed to handle complex categories such as fitness tutorials, cooking recipes, and action-oriented content, supporting clips up to 15 seconds in length across six aspect ratios.
Platform Integration and Safety Measures
Dreamina Seedance 2.0 is being integrated into CapCut’s AI Video and Video Studio tools, as well as ByteDance’s Dreamina and Pippit platforms. To mitigate risks, ByteDance has implemented strict safety protocols: the model cannot generate videos from images or clips containing real faces and includes blocks against the unauthorized generation of protected intellectual property. Furthermore, all content generated by the model will feature an invisible watermark to facilitate identification and rights management.
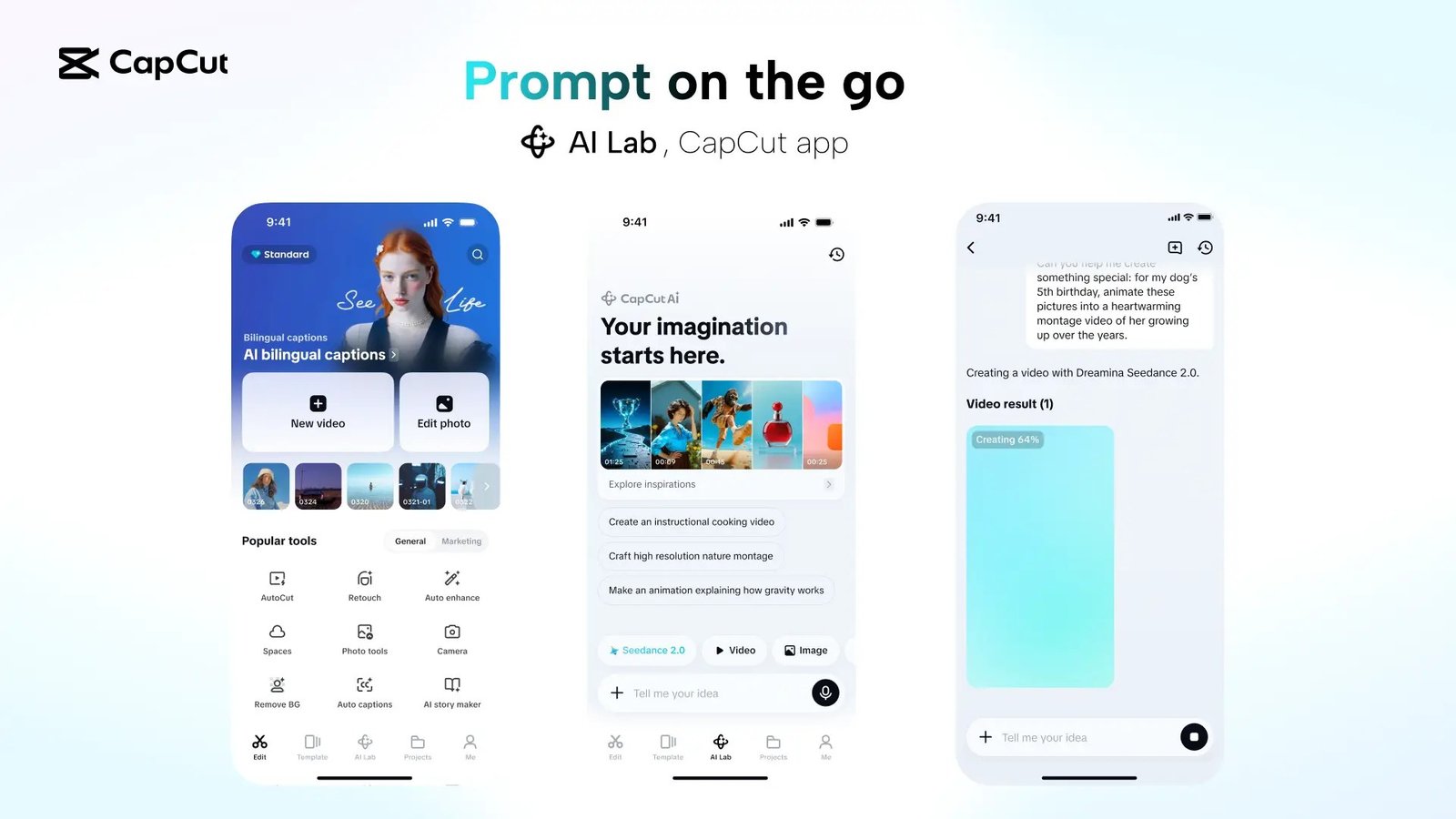
ByteDance intends to collaborate with creative communities and industry experts to iteratively refine the model’s capabilities as it continues its rollout.




